An exploratory dive into the IPL dataset (2020 vs other years)
In this set of fairly basic analysis on the IPL datasets, I look at whether 2020 was a particularly interesting year when viewed from different angles. Notwithstanding the fact that due to COVID-19, the 2020 IPL was played outside of India (This is only the second time in IPLs twelve year history that these games were played outside India. The last one was in South Africa in 2009), we would generally expect that with a series of illnesses, controversies etc., the performance of the 2020 IPL edition could be different.
The purpose of this analysis, for me, was to enhance my data exploration and understanding skills, which I eventually intend to use to model this information. I will dig into the analysis right way by first analyzing the number of matches played in this edition.

At 60 matches, it is one of the more standard editions of the games. This has been fairly consistent across the years, except for the period 2011 to 2013 when there were more than 70 matches played. I would suspect that this is because of the number of teams playing. Lets have a look.

So this largely seems the right reason. Every addition of team in the mix means that there are more round-robin matches played. In summary:
1. In 2011, two teams — Pune and Kochi came into the mix thereby adding a good deal of matches (at least 28 between them)
2. In 2012 however, even though one of the teams was not in vogue any more (i.e. Kochi), the minimum matches played increased from 13 to 15 indicating more round-robin style matches
3. In 2013 this further increased to a minimum of 16 matches played by any team. The format of the game was becoming lengthier.
4. It is also true at 2012 and 2013 saw the most number of teams participating (9 teams). This has leveled off to eight teams since then even though teams have gone off and come back in due to issues and scandals. For example, both Rajasthan Royals and Chennai Super Kings did not participate in the 2016 and 2017 editions of IPL as they were suspended. But they were replaced with Gujarat Lions and Pune Warriors.
So now that the matches have been largely explained, lets have a look at whether the time duration over which the matches were played were any different? I am curious about this since I know that due to COVID, this season was a far more extended one. Let me see how the data looks like:

So 2020 still wasn’t a particularly different year with the duration of the games spanning 52 days from 19 September to 10 November 2020. Though this is among the longest editions (longest ones being 53 days in 2012 and 2013), this is just a couple of days more than 2018 and 2019. I was expecting that the matches would be more dispersed this time around. Not true! The 2009 series (the one in South Africa) was the shortest one with 36 days.
Let us now look at how the matches panned out in terms of runs, average score per match, average score per innings and number of wickets dismissed in each of these matches:
First up, total runs scored:

The total runs scored in 2020 (19,416) was very similar to 2019 (19,434). The average runs scored per match therefore was very similar between the two editions (324 runs per match)
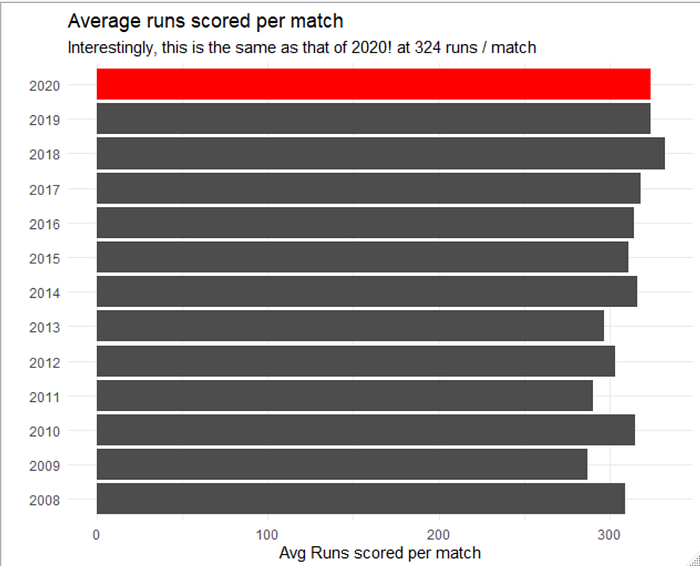
A look at the average score per innings indicates that 2020 was still an unremarkable year. To get this average score per innings, I have removed the runs scored in super overs as they are not technically an “innings” and would impair the computation of averages. The average score per innings in 2020 was 161 runs. Contrasting this to the 2018 edition where the average score per innings was at 166. The lowest however was in 2009 at 143 runs. I would expect that the South African pitches were not very conducive to high scoring games.
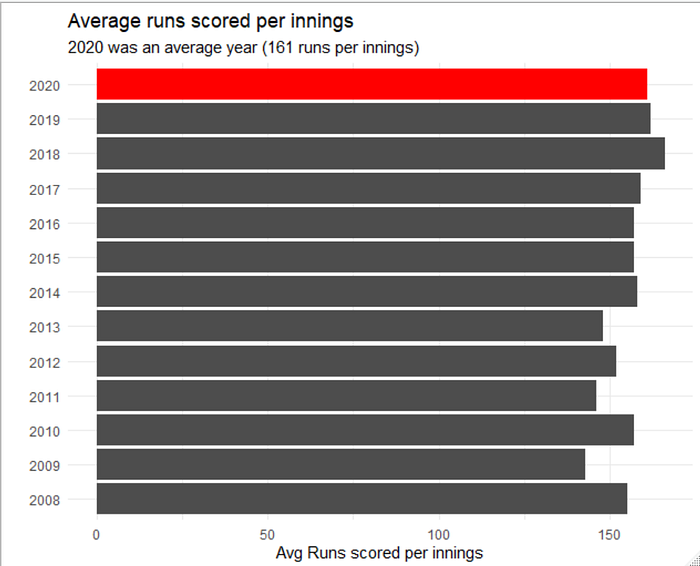
I would like to analyze this a little further using the individual match data. Let’s see if we can glean any meaningful analysis from it.
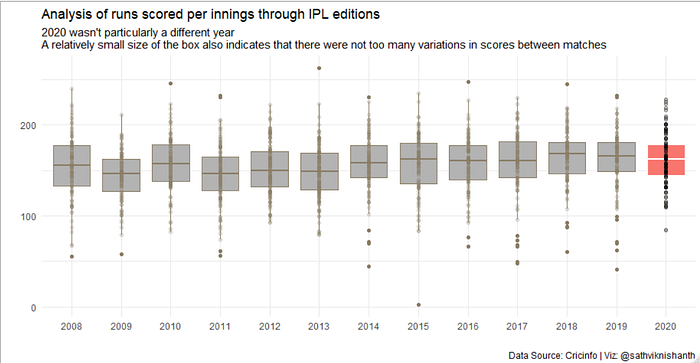
This analysis adds a little more color into the scoring patterns. We can see that 2020 was not a particularly exciting year in terms scores — No big outliers among high scoring games nor among low scoring games. There was a slightly marked increase in median scores per innings between 2015 to 2018 which has been falling since. The slightly more lower score in 2020 could also be explained by the fact that the venues were no longer those that the batsmen were accustomed to, considering this was being played out at Dubai. Nevertheless, one additional insight I would like to also takeaway from this is that it’s not been an “all-batsman” event like how most T-20 matches are made out to be. I do not see a runaway increase in scores indicating that the matches are becoming more batsmen friendly. The scores are still pretty tightly knit between the 150–180 range.
So overall, in my analysis so far, 2020 did not particularly stand-out till I started looking at some result information. Particularly this one.
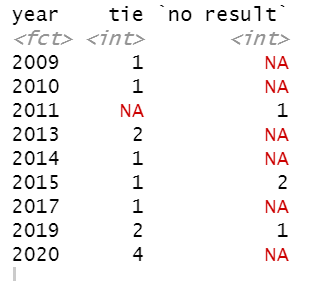
There were 4 ties in the 2020 edition! This is 100% more than any other edition of IPL. This got me thinking that the analysis of whether 2020 was really exciting from a sporting perspective, needs to be looked at from the point of view of how close these matches were. The small size of the box in the plot drawn above does indicate that there could have been more tighter matches in 2020 than in other seasons.
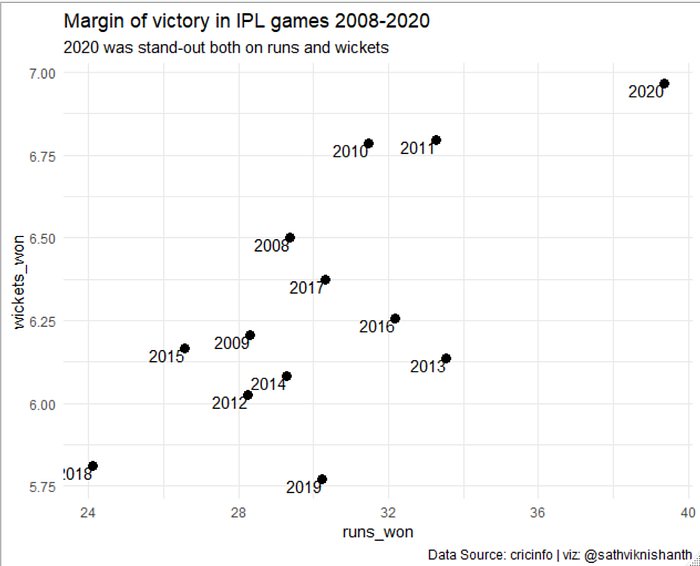
But lo behold! 2020 actually seems to be one of those years that stands apart in terms of the margin of victory, both from the wickets standpoint as well as from the margin of runs. The average runs by which the team won in 2020 was ~ 40 runs — Compare this to the 2018 edition when the margin was much smaller at 24 runs. Similarly, the wickets by which a team has won at 6.97 is much higher than say a 2019 set of matches where the margin was 5.7 wickets. This analysis does tell a slightly different story, albeit the fact that there were 4 ties does mean that the event did have a lot of it’s nail biting moments.
For this straight through analysis and writing, which has taken me roughly around 2.5 hours was quite joyful. I will stop my analysis for now and publish this section, not because there aren’t more questions to be asked (there are tons!), but because I would like to go have some tea :)